



İstatistikte, hipotezleri test ederken olası iki tür istatistiksel sonuç hatası vardır. Bunlara Tip 1 ve Tip 2 hata denir.
Şimdi hipotez nasıl kurulur buna bakalım: Öncelikle incelediğimiz 2 grup arasında anlamsal bir fark var mı yok mu? bunu incelediğimizi düşünelim. Kuracağımız Hipotezin adı H0 Hipotezi ya da diğer adıyla Boş Hipotez(Null hypothesis). Her zaman H0 Hipotezi gruplar arasında fark olmadığı üzerine kurulur, eğer aksi olursa H0 Hipotezi reddedilir.
Kısaca H0 Hipotezi aşağıdaki gibi şekilde oluşturulmalıdır:
H0: Gruplar arasında fark yoktur

Teorik bölümünü geçtik şimdi daha farklı ifadeler ile konuyu açıklığa kavuşturalım.
Tip 1 Hata: H0 hipotezi gerçekte doğru iken, bu hipotezin yanlışlıkla reddedilmesidir.
Tip 2 Hata: H0 hipotezi gerçekte yanlış iken, bu hipotezin yanlışlıkla kabul edilmesidir.
Tip 1 ve Tip 2 hatayı anlamakta biraz zorlanabilirsiniz ancak farklı ifadeler ile devam edelim:
Tip 1 Hata: Hamile olması imkansız olan birinin(örn:bir erkeğin) hamile olduğunu iddia etmek(hasta olmayan biri için riskli, gereksiz, ileri tetkikler, yanlış tedavi, yanlış tanımlama ile sonuçlanır )
Tip 2 Hata: Gerçekten de hamile bir kadının ultrasonuna bakıp da, doktor hatası nedeniyle hamile olmadığını iddia etmek(Hasta birisi için tedavinin gecikmesi ile sonuçlanır)

- True Positive (TP): Hamile bir kadına hamilesin demek.
- True Negative (TN): Bir erkeğe hamile değilsin demek.
- False Positive (FP): Bir Erkeğe hamilesin demek.Tip 1 Hata (Hatalı Pozitif)
- False Negative (FN): Hamile olan bir kadına hamile değilsin demek.Tip 2 Hata (Hatalı Negatif)
Hamile olması imkansız olan birinin hamile olduğunu iddia etmek hatalı pozitiftir. Gerçekten de hamile bir kadının ultrasonuna bakıp da, doktor hatası nedeniyle hamile olmadığını iddia etmek ise tip 2 hatası olur.
Şimdi basit bir örnek ile devam edelim, hazır bir veri kullanalım:
import pandas as pd
# Gerekli kütüphane
from sklearn import metrics
# Basit bir liste
y_pred = [1,1,1,0,0,1,0,1,0,0,0,1,0,0,1,1,0,0,1,1,0,0,0,0,1,1,0]
y_test = [1,0,1,1,0,0,1,0,0,0,0,1,0,0,1,1,0,0,0,1,0,0,0,0,0,0,1]
# Python listemizi pandas series yapalım
y_pred = pd.Series(y_pred)
# Python listemizi pandas series yapalım
y_test = pd.Series(y_test)
# Hata matrisini oluşturalım
metrics.confusion_matrix(y_test, y_pred)
array([[12, 6],
[ 3, 6]])
Elde ettiğimiz hata matrisini daha iyi anlamak için aşağıda tablo üzerine tahminleri değerlendirelim:
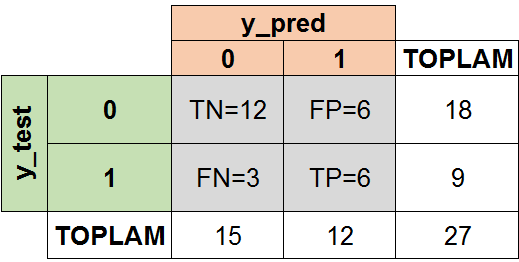
- True Positive (TP): Hamile bir kadına hamilesin demek.
- True Negative (TN): Bir erkeğe hamile değilsin demek.
- False Positive (FP): Bir Erkeğe hamilesin demek.Tip 1 Hata (Hatalı Pozitif)
- False Negative (FN): Hamile olan bir kadına hamile değilsin demek.Tip 2 Hata (Hatalı Negatif)
Hata Matrisinden Elde Edilen Bazı Metrikler
Makine öğrenmesi algoritmalarının çalıştığımız veriler üzerinde ne kadar doğru tahmin yapabildiklerini ölçmek için çeşitli metriklere bakabiliriz. Bu metrikler: Accuracy, Error rate, Precision, Recall(Sensitivity), Specificity (Selectivity) ve F Score'dur.
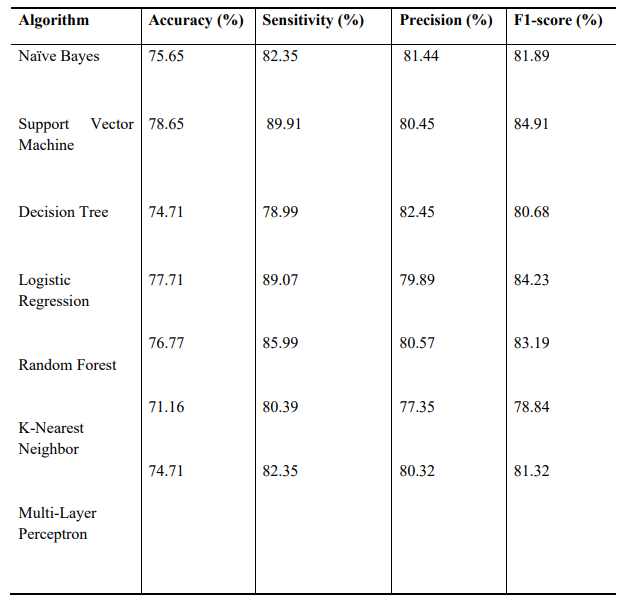
Aşağıdaki resim başka bir bilimsel makaleden alınmış bazı algoritmaların sonuç değerlerini gösteren örnek bir tablodur, yukarıda ki verilerle bir ilişkisi yoktur. Aşağıdaki gibi bir tablodaki metriklerin başarılarına bakarak elinizdeki verilere en uygun modeli seçmek size kalmış.
Şimdi bu metrikler nasıl hesaplanır ve ne anlam ifade eder sırasıyla bakalım.
Doğruluk (Classification Accuracy-Accuracy skoru)
Accuracy, anlaşılması ve yorumlanması en basit ölçütlerden birisidir. Bu istatistik doğru tahmin oranıdır. Doğru tahmin oranı, etiketleri doğru tahmin edilen test gözlemlerinin toplam test gözlemlerinin sayısına bölünmesidir. Makine öğrenmesi sınıflandırma algoritmalarının testlerinde sıklıkla kullanılır. Accuracy skoru aşağıdaki gibi hesaplanır. Accuracy skoru 0 ve 1 arasında olup 1’e yaklaşan skorlarda model başarılı kabul edilir.
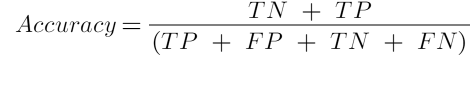
Accuracy(doğruluk), Python ile aşağıdaki gibi hesaplanabilir.
dogruluk = metrics.accuracy_score(y_test, y_pred)
#dogruluk
#0.66666666666666663
Hata Oranı (Error Rate / Misclassification Rate)
Genel olarak, sınıflayıcının ne sıklıkta yanlış tahmin ettiğinin bir ölçüsüdür. Hata Oranı olarak da bilinir (Error Rate).

Error Rate(Hata oranı), Python ile aşağıdaki gibi hesaplanabilir.
1 - metrics.accuracy_score(y_test, y_pred)
#0.33333333333333337
Precision(Kesinlik)
Tahmin ettiğim örnekler içerisinde gerçekten kaç tanesi doğru? sorusunun cevabıdır. Yani pozitif tahminlerin toplam pozitiflere oranı.
Hamile dediklerimizin gerçekten kaçı hamile?
Precision’la recall ters orantılıdır ve ikisinin arasında bir denge tutturmak gerekir.
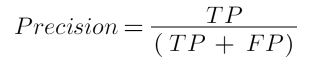
Precision(Kesinlik), Python ile aşağıdaki gibi hesaplanabilir.
metrics.precision_score(y_test, y_pred)
0.5
True Positive Rate(Duyarlılık, Sensitivity veya Recall)
Recall yada Sensitivity, sınıflar içerisinde doğru olduğu bilinen gözlemlerin doğru olarak tahmin edilenlerinin bütün doğru olduğu bilinen gözlemlere oranıdır. Pozitif sınıfa ait örneklerden kaç tanesini doğru tahmin ettim? sorusunun cevabıdır.
Hamile olanları doğru tespit etme oranımız.
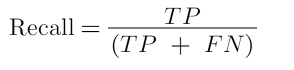
Recall, Python ile aşağıdaki gibi hesaplanabilir.
# Recall
print(metrics.recall_score(y_test, y_pred))
# ÇIKTI: 0.6666666666666666
False Positive Rate, Specificity (SPC-Seçicilik), Selectivity, True negative rate (TNR)
Gerçekte hamile olmayanlar arasında testin negatif sonuç verme oranı
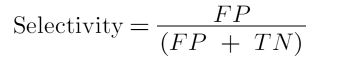
F Score
Precision ve recall’u dengelemede devreye F1-Score giriyor. F1-Score precision ve recall’un harmonik ortalaması. Modelin gücü, Precision ile Recall değerlerinin harmonik ortalamasıdır. Bu sebeple başarının iyi bir göstergesidir.
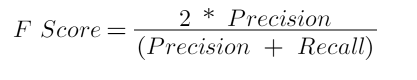
F Score, Python ile aşağıdaki gibi hesaplanabilir.
# F1-Score
print(metrics.f1_score(y_test, y_pred))
# ÇIKTI: 0.5714285714285715
